这是2021-1-23写的笔记,但当时尚未完成,一直搁置至今。近期维护博客和公众号才想起,尽量补全内容,重新发布。
背景
最近工作稍微忙了些,好久没发文章了。三个月前开始参与了一个Windows App组的新项目,但原先项目的事情常常也需要推进一些,大脑每天在几个项目之间来回切换,回到家就只想放空自己,当然不会想着读书写文章了。另外,业余时间也有积累其它的写作,只是都是些半成品,不便公开。没想到,就这样,一晃半年过去了。临近春节了,很多事情都在做总结,也可以逐渐慢下来了。不妨再记录一点吧,毕竟又遇到了一本有趣的书。
一直以来,我都想找到一本讲解架构设计的书籍。毕竟,小型程序我写的也算不少了,积累了不少开发技巧方面的经验,算是能够游刃有余的实现各式各样简单的需求。然而,放眼各个行业,真正创造巨大价值的软件,绝不是一个个的小程序,而往往是一些凝聚了技术人员数十年心血的程序。
我不是否定小型程序。很多时候,基于一个极具创意的点子,开发一个小型程序,能够满足特定人群的需求,就能开辟可观的市场,创造不菲的价值。可是这些点子,常常可复制性很强,实效性可能也很强。最关键的是,这样的点子也越来越不容易想到了,或者说太多人都可以想得到了。因此,我只是觉得这里的竞争太过激烈,变化也太过频繁。这些小型程序创造的价值似乎都是压榨出来的,尽管不可否定,却又有点小打小闹。不过,说到底这也是我的偏见。简而言之,如果你问我,一个用户交互优化到极致的笔记App与Office这个臃肿的庞然大物相比,谁更有价值,我会毫不犹豫地回答后者。我相信,尽管前者能让生活变得更美好,后者却可以让社会整体运转的效率得到巨大提升。
大型程序不仅仅拥有积累了长期的技术,还整合了行业内的各类需求。另外,能够不断发展进化数十年的程序,也是被时间检验过的,必然拥有灵活稳健的架构,以不断适应各类新需求,实践各类新技术。这一点是最难的。很多软件在发展过程中,为了满足各式各样的需求,很可能会不断地腐化。新旧技术杂糅在一起,各类需求的程序逻辑交织在一起,难舍难分。那么怎么解决这种问题呢?
我先是打算在实践中寻求答案。在单位,我参与一个从零开始的项目开发。由于人手不多,我有幸能够做一些架构设计。项目倒也不算大型,但相当底层。底层项目往往需要支撑上层更加丰富多样的模块,因此尽管代码量不比一些业务逻辑丰富的程序,却也决不能算作小型程序。项目架构自然是重中之重。然而,在架构设计过程中,我时常感到力不从心。
痛苦的直接来源,就是不知道如何界定不同模块的边界。而导致这一问题的关键原因之一,是对需求的理解不够深刻。不过这个问题在经过与同事和用户的不断沟通后,可以逐渐被解决。只是如果还有下次,我一定会吸取教训,在最开始的时候就对需求进行深入地讨论。然而,解决这一问题之后,仍不足以让我清晰地确定模块边界。比如,两个组件有很多相似的行为,但处理的输入数据不尽相同,输出格式也不同。那么,这两个组件要不要实现一个共同的接口?输入的处理逻辑是否要拆分成单独的模块?输出呢?
如果输入和输出与组件本身的逻辑耦合在一起,可能我们就很难让两个组件实现共同的接口;但好处是,输入的数据可以直接拿来处理,然后再直接被输出。反之,如果将这几部分解耦,分成不同模块,我们也许就需要设计输入和输出数据的中间表示,这样才能统一它们的接口;输入和输出模块则需要将数据在不同格式与中间表示之间进行转换,这样不仅逻辑会复杂很多,还很容易带来一些性能上的损失。因此,这里需要权衡,需要妥协。痛苦的根源就是妥协,因为把握不好这个度。
后来,我想在书中寻找答案。略读了不少《软件工程》书籍中架构设计相关的内容,但大多都相当高屋建瓴,不容易落实到实践中;网上检索一些所谓架构设计的资料,又几乎都是现在流行的网络后端架构的文章。我一度非常郁闷,直到在图书馆看到了《大规模C++程序设计》这本书。这本书给我最大的启发,就是架构上的一些设计是可以被量化的,而这些量化指标能够作为我们权衡利弊的最佳参考依据。
我不多作介绍,直接上一些(仅前五章)书摘吧(算是总结,不总是摘抄):
第0章:概述
大规模程序的常见问题
循环依赖
例如实现一个由点和边构成的图,我们常常会在表示点的类里记录与它相连的所有边,同时在表示边的类里记录它所连接的点。另外,每一个点和边可能还会记录它们所属的图,而图可能又存储了全部的点和边……
这里的依赖关系显然是循环的,但这种设计非常普遍。循环依赖会导致紧密耦合,无法拆分。对这样的程序进行模块化测试是不可能的,维护起来是一场噩梦。
没有循环依赖的层次化设计会更有助于理解、测试和增量复用。
过度的链接时依赖
类会随着功能需求的增加而不断膨胀,这会使得程序体积增大,链接时间增加。
过度的编译时依赖
改一个头文件可能引起很多编译单元重新编译。
全局符号名称
全局符号可能造成名字冲突。另外,定位一个全局符号的声明或定义也是很困难的。
全局符号通常都是通过typedef、enum引入的。
逻辑设计和物理设计
我们常常只关心逻辑设计而忽略了物理设计。物理设计指与系统物理实体(文件、目录、库等)密切联系的问题,以及物理实体之间的编译时依赖或链接时依赖的问题。例如,某个头文件应不应该在另一个头文件引用,或者应不应该在源程序中引用,这种问题就属于物理设计的范畴。
小型项目可以很容易地放入一个目录,因此很少关注物理设计;大型项目更加需要合理的物理设计。
复用
复用意味着耦合,而复用中的耦合是我们不愿意看到的。
如果很多程序员使用同样的标准组件而不需要改变它的功能,复用很可能是正确合理的。但如果很多用户在使用公共组件时,总是寻求功能的增强或改进,这时复用就会导致分歧:满足某些用户需求的功能,很可能对其他用户来说是一种冗余的干扰;这个组件最后可能成为一个臃肿的庞然大物。
为了成功复用,组件或子系统一定不要与一大段不必要的代码绑定在一起(不必链接系统的其他部分)。
大型项目得益于它们的实现者知道什么时候复用代码,什么时候让代码可复用。
第1章:预备知识
类成员布局
class Car {
public:
// Creators
Car(int cost = 0);
Car(const Car& car);
~Car();
// Manipulators
Car& operator=(const Car& car);
void addFuel(double numberOfGallons);
void drive(double deltaGasPedal);
// Accessors
double getFuel() const;
double getSpeed() const;
};
- Creator用于构造或析构对象
- Manipulator用于修改对象,即非const成员函数
- Accessor用于访问对象,即const成员函数
没必要教条地用getter/setter成双对去暴露数据成员,应该根据修改和访问的需要去设计接口。
逻辑设计表示法
Is-A
class Car : public Vehicle {};
Car is a Vehicle.
Uses-In-The-Interface
class Car {
public:
void addFuel(Gas *);
};
Car uses Gas in the interface.
Uses-In-Name-Only
这是一种特殊的Uses in the interface。
下例中的Vehicle无需知道Gas的内存布局。
class Gas;
class Vehicle {
public:
virtual void addFueld(Gas *) = 0;
};
Vehicle uses Gas in name only.
这种情况下,不引入物理依赖(Vehicle.h不需要include Gas.h)。
Uses-In-The-Implementation
class Car {
Engine d_engine;
};
Car uses Engine in the implementation.
第2章:基本规则
包含卫哨(Include Guard)
// a.h
#ifndef A_H
#define A_H
// ...
#endif // A_H
// b.h
#ifndef B_H
#define B_H
#include "a.h"
// ...
#endif // B_H
// c.h
#ifndef C_H
#define C_H
#include "a.h"
#include "b.h"
// ...
#endif // C_H
// main.c
#include "a.h"
#include "b.h"
#include "c.h"
编译main.c时,三个头文件通过包含卫哨保证其内容只被引用一次,但每一个头文件读入的次数却仍然很多:a.h需要被读入3次,b.h需要被读入2次。 尽管后面几次读入只是看到宏定义就可以结束了,这反复的读入却仍然是不可避免的。如果头文件数量很多,引用关系也很随意,那么编译时间就会受到严重影响。
冗余卫哨
// a.h
#ifndef A_H
#define A_H
// ...
#endif // A_H
// b.h
#ifndef B_H
#define B_H
#ifndef A_H
#include "a.h"
#endif // A_H
// ...
#endif // B_H
// c.h
#ifndef C_H
#define C_H
#ifndef A_H
#include "a.h"
#endif // A_H
#ifndef B_H
#include "b.h"
#endif // B_H
// ...
#endif // C_H
这样写能够避免编译复杂度达到O(N^2)。
在源程序中无需使用冗余卫哨,因为最坏情况下复杂度也只是线性的。
第3章:组件
组件(而不是类)是设计基本单位。
- 组件组合了跨越许多逻辑实体的内聚功能
- 组件不一定是单一实体,也可能不包含类
- 组件可以作为单一的单位从系统中剥离开,不必重写代码即可在另一个系统中复用。
组件的逻辑接口是以编程方式可访问或可被用户检测到的。 组件的物理接口是它头文件中的所有信息。
关于逻辑视图和物理视图的例子
Stack的逻辑视图包含Stack和StackIter两个逻辑实体,Stack会在接口中用到StackIter。 Stack的物理视图包含stack.h和stack.c两个物理实体,stack.c会包含stack.h。
依赖关系
如果编译或链接组件y,需要组件x,则组件y依赖于组件x。
友元关系
组件内的友元关系是组件的实现细节。
不要把距离太远的另一组件的逻辑实体作为友元,容易破坏封装。
但其实封装非常好破坏,只需要把下面这行代码放到一切头文件引用之前:
#define private public
第4章:物理层
累积组件依赖(CCD, Cumulative Component Dependency)
累积组件依赖是对一个子系统内所有组件进行增量测试时,测试每个组件$ C_i $时所需要的组件数量的总和。
对于循环依赖图来说,每个组件都直接或间接地依赖全部其他组件,此时:
设N为系统中组件的数量,
平衡二叉树型地物理依赖系统的CCD如下:
平均组件依赖(ACD, Average Component Dependency)
ACD指一个子系统的CCD与系统中的组件数量N的比值:
标准累积组件依赖(NCCD)
标准累积组件依赖指包含N个组件的子系统CCD值与相同大小的平衡二叉树型系统CCD值的比值:
如果NCCD小于1,则认为子系统较为水平化、松耦合,缺少复用;如果NCCD大于1,则子系统较为垂直、紧密耦合,复用较多。 如果NCCD远远大于1,则系统中可能有明显的循环物理依赖。
目标
最小化一个给定组件集合的CCD是一个设计目标,但也要合理追求这个目标。
CCD度量方法帮助我们最小化依赖,NCCD则帮助我们将物理依赖分成水平的、树形的、垂直的和循环依赖的。
第5章:层次化
循环物理依赖的来源
这里介绍三种来源:增强、遍历方法和内在的相互依赖。
增强
随着客户需求变化,我们可能会对系统功能进行增强,此时的考虑不周可能引起不必要的循环依赖。
两个组件通过#include相互引用,会引入循环物理依赖。例如,我们可能某天希望类A和B能够通过另一个类来构造自己(相互转换):
// a.h
#include "b.h"
class A {
A(const B& b);
};
// b.h
#include "a.h"
class B {
B(const A& a);
}
虽然我们可以将对对方的引用挪到源程序中,但这并不能消除二者的物理耦合,它们仍然相互依赖:
// a.h
class B;
class A {
A(const B& b);
};
// b.h
class A;
class B {
B(const A& a);
}
便利方法
还有的时候,大家图省事,就会导致不良设计。
例如,有一个Shape抽象类,它有三个子类Triangle、Circle、Square。我们突然接到一个需求,希望能通过形状的名称字符串来创建新的Shape。此时,我们很可能为了方便就在Shape类中增加了一个静态方法:
class Shape {
Shape *Create(const char *s);
};
Shape *Shape::Create(const char *s) {
if (0 == strcmp(s, "Circle")) {
return new Circle();
} else if (0 == strcmp(s, "Triangle")) {
return new Triangle();
} else if (0 == strcmp(s, "Square")) {
return new Square();
} else {
return nullptr;
}
}
这种实现使得Shape与他所有的子类形成了相互依赖关系。
内在的相互依赖
这是一种天然的循环依赖。
例如实现图的节点和边数据结构时,可能希望节点提供一个方法获取到与之相连的所有边,同时又希望边提供一个方法获取到与之相连的所有节点。这种设计中,节点和边一定是相互依赖的。
升级
有时我们需要Rectangle和Window两个类可以互相转换(也就是构造函数中产生了相互引用)。
// rectangle.h
class Window;
class Rectangle {
Rectangle(const Window& w);
};
// window.h
class Rectangle;
class Window {
Window(const Rectangle& r);
};
为了避免这种情况,我们通常会将依赖转换为单向依赖。例如:
// rectangle.h
class Rectangle { };
// window.h
class Rectangle;
class Window {
Window(const Rectangle& r);
};
但到底谁依赖谁呢?可能Rectangle看起来是一个更基础的类型,那么让Window依赖Rectangle似乎比较合理。
不过,如果有时候这种依赖关系并不明显,我们可以将这个问题升级给上层:
// rectangle.h
class Rectangle { };
// window.h
class Window{ };
// utils.h
#include "rectangle.h"
#include "window.h"
struct Util {
static Window toWindow(const Rectangle& r);
static Rectangle toRectangle(const Window& w);
};
降级
两个Util类之间可能互相借助对方的功能完成了自身的一些功能,因此产生了循环引用。
// geomutil.h
class Point;
class Line;
class Polygon;
struct GeomUtil {
static int isInside(const Polygon& polygon, const Point& point); // 依赖 GeomUtil2::doesIntersect
static int areColinear(const Line& line1, const Line& line2);
static int areParallel(const Line& line1, const Line& line2);
};
// geomutil2.h
class Line;
class Polygon;
struct GeomUtil2 {
static int crossesSelf(const Polygon& polygon); // 依赖 GeomUtil::areColinear
static int doesIntersect(const Line& line1, const Line& line2);
};
此时我们可以将出现互相引用的功能抽出来,降级为二者的依赖,例如创建一个UtilCore。
// geomutilcore.h
class Point;
class Line;
class Polygon;
struct GeomUtilCore {
static int doesIntersect(const Line& line1, const Line& line2);
static int areColinear(const Line& line1, const Line& line2);
};
// geomutil.h
struct GeomUtil {
static int isInside(const Polygon& polygon, const Point& point); // 依赖 GeomUtilCore::doesIntersect
static int areParallel(const Line& line1, const Line& line2);
};
// geomutil2.h
struct GeomUtil2 {
static int crossesSelf(const Polygon& polygon); // 依赖 GeomUtilCore::areColinear
};
对于一些不存在循环引用的系统,降级也是很好用的。有时组件A只是依赖组件B的非常小的子集,那么可以将这部分子集 降级,让A和B都依赖它。这样可以降低CCD指标,减少复杂度,提高代码复用。
不透明指针
不透明指针,即指向一个未知内存布局的类型的指针。使用不透明指针相当于Uses in name only。
有时候,一个容器中的每一个元素可能都包含一个指向容器的父指针,这样就会出现循环引用。
为了解决这个问题,我们可以将元素中的指针改为不透明指针,然后提供一个公开接口以获取该指针。 任何在元素的类型中需要父指针来实现具体功能的方法,应当移到容器中。如下例:
// screen.h
class Widget;
class Screen {
Widget *widgets;
public:
void addWidget(const Widget& w);
int numWidgets() const;
};
// widget.h
class Screen;
class Widget {
Screen *parent;
public:
Widget(Screen *screen);
int numWidgetsInParentScreen() const;
};
// widget.cpp
#include "widget.h"
#include "screen.h"
int Widget::numWidgetsInParentScreen() const {
return parent->numWidgets(); // 依赖Screen
}
重构后:
// screen.h
class Widget;
class Screen {
Widget *widgets;
public:
void addWidget(const Widget& w);
int numWidgets() const;
};
// widget.h
class Screen;
class Widget {
Screen *parent; // 现在这是一个不透明指针
public:
Widget(Screen *screen);
Screen* parentScreen() const;
};
// widget.cpp
#include "widget.h"
// #include "screen.h" 不再需要了
Screen* Widget::parentScreen() const {
return parent;
}
调用widget.parentScreen()->numWidgets()即可实现原先Widget::numWidgetsInParentScreen()的功能。
哑数据(Dumb Data)
其实我觉得翻译成哑数据谁都看不懂了……我理解它就是一个ID。当然更广义一点,就是一个作为代号的数据。
书中说它是对不透明指针的泛化(广义化)。不透明指针还需要uses in name only,哑数据那可能就是一个int。
冗余
复用代码会带来耦合,因此有时候冗余的重复代码可能带来比复用更大的价值。
回调
回调往往是不好的架构的征兆……尽管它能用于解耦。因此,回调应是最后才考虑的方法。
管理器类
假设我们要实现一个图,Edge和Node两个类的关系是比较复杂的。
一个简单的设计,可能是认为Edge级别更高,所有与Edge相关的事情Node是无法完成的。
Node可以拥有与之相连的所有Edge的集合,但是Uses in name only。
class Node {
friend Edge; // 跨文件的友元
void addEdge(Edge *edge); // 私有成员,仅被Edge调用
Node(const Node&) = delete;
Node& operator=(const Node&) = delete;
public:
Node(const char* name); // 谁来构造和析构Node,谁拥有Node?
~Node();
const char* name() const;
int numEdges() const;
Edge& edge(int index) const;
这样是很不好的设计。举个例子,析构一个Node会发生什么?
因为Node不会做任何与Edge相关的事情,因此析构Node就仅仅是析构了Node。
此时通过Edge去访问其端点Node时就可能访问到了一个已经被析构的Node。
我们需要一个管理器类,对于图来说,我们可以创建一个Graph类。
Node和Edge可以位于同一级别,Graph位于更高级别。Graph拥有所有的Node和Edge,
Node和Edge之间仅Uses in name only。
删除Node的方法显然应该由管理器类Graph提供,它会处理好所有相关Node和Edge的析构。
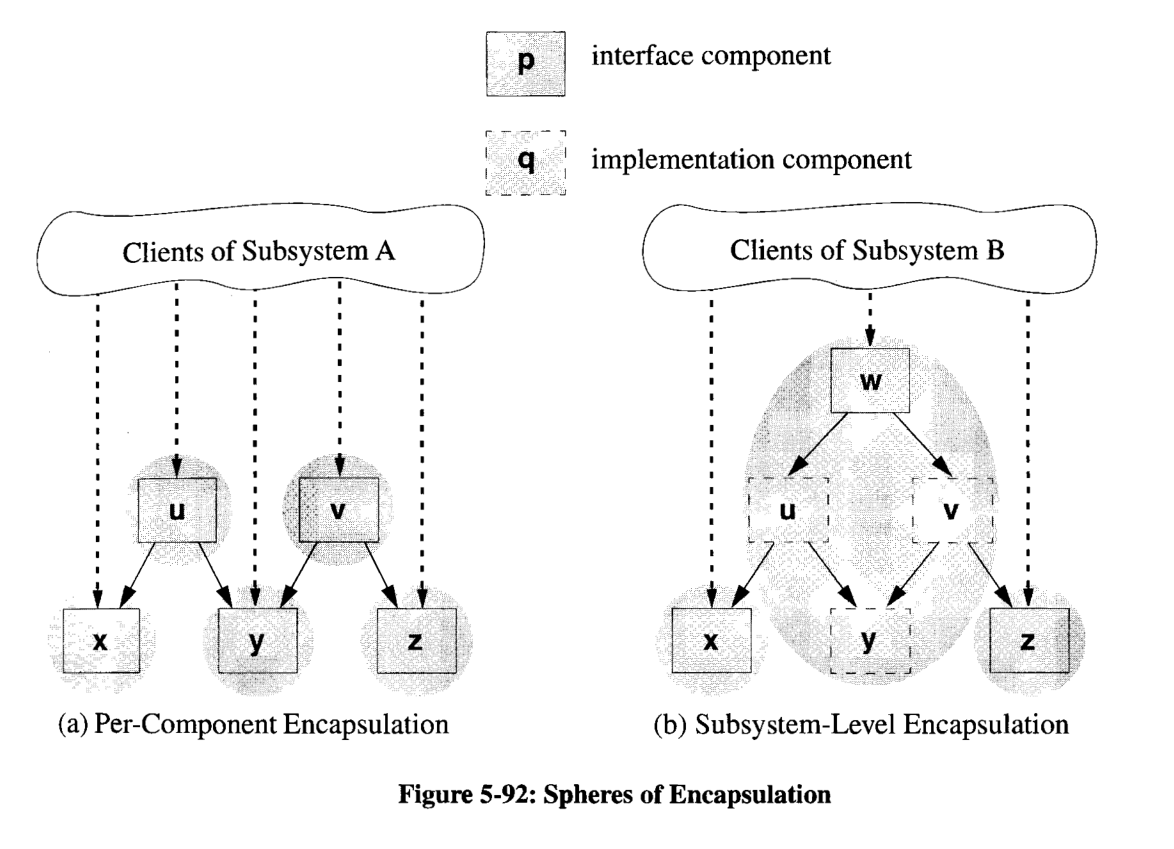
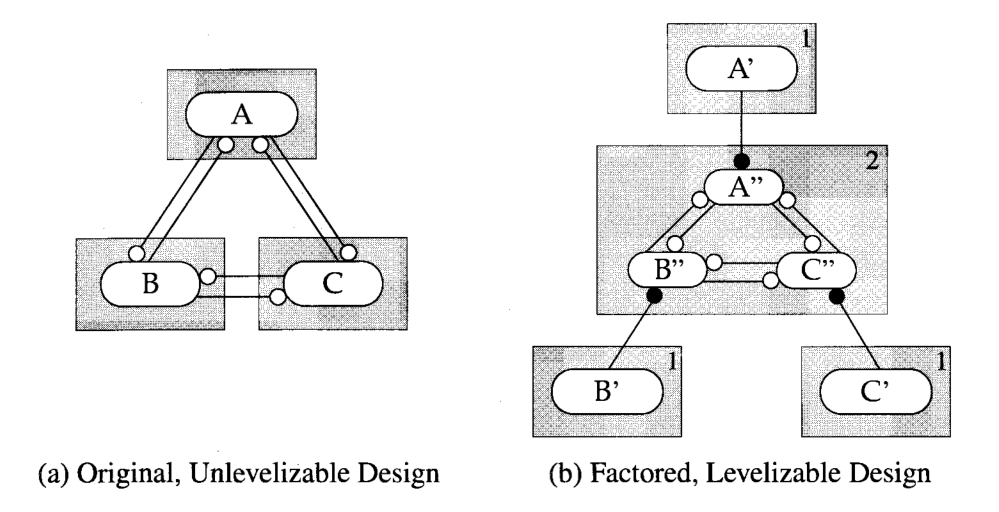
内聚分解(Factoring)
提取内聚的部分作为低级别组件:
升级封装
我们知道封装很重要,可以用于隐藏实现细节。但何谓实现细节?
如果每一个类都只是提供公开接口,拥有一大堆实现细节,那是很笨重的,也不利于复用。
是否是实现细节是和当前抽象层级相关的。我们完全可以公开一些复杂逻辑的类,在上层 在创建一个包装类(Wrapper)引用这些实现复杂逻辑的类并将其隐藏封装。
所谓封装一个类型,是隐藏他的使用,而非隐藏这个类型本身。